October 2023 Project Updates
By Kathy Davis
Check out the latest reports from our developers working on shorter-term projects.
Biff: Jacob O’Bryant
Bosquet: Zygis Medelis
Clojure Camp: Daniel Higginbotham
Deps-try: Gert Goet
GDL: Michael Sappler
Jank: Jeaye Wilkerson
Neanderthal: Dragan Duric
Quil: Jack Rusher and Charles Comstock
Biff: Jacob O’Bryant
2023 Q3 Funding Report 1. Published 15 October 2023.
- Published an essay Understanding htmx. Seems to have been well received. It’s had 1.4k page hits.
- Wrote the first half of another essay, How does XTDB compare to other databases? (working title)
- Studied some beginner SEO resources (this and this) and did some keyword research.
My conclusion is that the only Clojure-related search query with enough traffic to be worth trying to rank for is simply “clojure” itself. (e.g. “clojure web framework” seems like an obvious candidate, but Google says it gets only 10 - 100 searches per month.)
Looking at the current Google results for “clojure”, it actually seems like it might be possible eventually to rank in the second half of the page. But either way, I don’t think it’s worth trying to write about any particular topics/go after any particular search keywords; I’ll just keep writing whatever seems most useful based on community feedback/gut feel. And maybe at some point, I’ll make sure I have a handful of pages that would at least be good candidates for the “clojure” results page–like my existing why clojure essay, and perhaps a curated list of learning resources.
I would’ve liked to have written at least three essays at this point instead of just one and a half, but I had some stuff come up. The next six weekends are clear though :). Things I’d like to get done in that time:
- Finish my current essay on XTDB
- Write an essay about Biff’s rationale and philosophy
- Write a framework comparison document that describes the differences between Biff and Kit/Fulcro/rolling your own.
- Write several how-tos focused on swapping out Biff’s defaults: replace XTDB with Postgres/SQLite/Datomic; deploy with Docker instead of on a plain VM; replace htmx with re-frame.
The remaining how-tos and the Biff-from-scratch guide (see the content
library roadmap) will need to wait until later.
Bosquet: Zygis Medelis
2023 Q3 Funding Report 1. Published 30 September 2023.
Goals
The main development direction for Bosquet is to provide an environment where LLM apps can execute autonomously. It needs to provide facilities for LLM agents to plan actions, use tools, and have memory access that enables this behavior. Initial functionality providing developers with prompt engineering, chaining, and completions remains Bosquet’s integral part.
Changes
Integrant-based system management
Autonomous agents need unified access to Memory, LLM Services, Planning, Tools, and other components. Integrant-based component management now added to Bosquet allows it. As part of the current release - LLM Services and Memory are declared via the Integrant system.
Bosquet Component configuration is implemented with juxt/aero library for added flexibility.
Multi LLM service support
Alongside previously available Open AI access (via wkok/openai-clojure), Bosquet now supports Cohere LLM (via danielsz/cohere-clojure).
Having access to different LLMs is not sufficient for autonomous agent execution. LLM Service components need to have well-defined input/output shapes for the agent to work with. Bosquet started adding schema definitions (done with metosin/malli) to declare the model’s capabilities and data formats (initial development stage).
Chat mode support
Bosquet had a gap in its functionality by not supporting chat mode. Now supported and based on ChatML. Chat mode benefits from existing Bosquet prompt management facilities, like Selmer templating, and Pathom based template chaining.
Memory
A critical component for further Bosquet development and coming up with a satisfactory architecture is proving to be hard. The current Bosquet release declares the Memory system that jacks into AI completion workflow to record AI interactions and inject relevant recalled memories into the prompt context.
Memory is implemented via Clojure protocols to enable pluggable memory storage, memory recall, and memory encoding algorithms. As part of the current release, a SimpleMemory is added. It uses an in-memory atom for storage and the most recent memory access recall.
Documentation
Bosquet already covers different and complex concepts of working with LLMs. It has accumulated out-of-order documents, descriptions that are obscure, or superseded. To address the lack of good Bosquet work explanations, I have started preparing a new documentation site https://zmedelis.github.io/bosquet/
Clojure Camp: Daniel Higginbotham
2023 Q2 Funding Report 3. Published 17 October 2023
Since our last update, we have continued exploring ways to partner with industry leaders to facilitate the process of connecting junior developers with Clojure jobs. We have a roadmap for engaging with partners over the next couple months, which will we be publicly sharing in the coming weeks.
Additionally, we’ve spent significant time exploring options to incorporate paid training in our offerings. The motivation for this was to find ways to develop Clojure Camp more sustainably. We decided that, for the near future, we want to focus our efforts on our vision of fostering a free, welcoming, friendly, and diverse peer learning community.
In addition to this organizational, administrative work, we’ve continued running our weekly study group sessions and improving our learning materials.
Finally, a piece of awesome news: one of our campers has landed a Clojure job! This is his her first programming job, and we are so thrilled for her!
Thank you, Clojurists Together, for your support in doing this work!
Deps-try: Gert Goet
2023 Q3 Funding Report 1. Published 18 October 2023.
I’ve been working on recipe functionality for deps-try (a tool to quickly try out Clojure libraries on rebel-readline).
I worked out a POC to explore what it would entail. The majority of the time went into working out some gnarly Java interop related to JLine’s history classes.
With this hurdle taken, and having worked out most of the options and flags for the CLI, I’m currently turning the POC into code for the mainline.
I’m looking forward to replace example code in some of my other projects, with a simple oneliner, e.g. deps-try --recipe malli-select/intro.
Planned future work
- Listing recipes: Showing a table with all the recipes from the repository.
- Allowing for recipe shortnames: Instead of providing a full url/path, just say
deps-try --recipe malli/data-generation. - Having a
--recipe-nsto only get the ns-form from the recipe in your history for when you only want the deps and the requires but nothing else in the history. - Turn some guides from clojure.org into recipes
Potential directions
- Having repositories with recipes: This would allow for using shorter names to load recipes also for non-builtin recipes.
- Supporting jvm-options and custom mvn-repositories: As this has potential security implications, this would best be combined with (trusted) repositories.
- A repository can have a TRYME file which functions as a recipe
Keep an eye on the unstable releases the coming weeks if you want to testdrive the new functionality!
GDL: Michael Sappler
2023 Q3 Funding Report 1. Published 15 October 2023.
What I have done in the last 1.5 months:
GDL
- extended scene2d API
- scene2d.ui is a simple&powerful GUI library included in libgdx. Example apps using it: hyperlap2d, spine.
- now 3 namespaces:
gdl.scene2d.ui/gdl.scene2d.actor/gdl.scene2d.stageinstead ofgdl.ui(before).
- use vis-ui for the scene2d GUI widgets (a java library advanced functionality based on top of libgdx.scene2d.ui ).
- some simplifications/refactorings.
- next goal: remove the global states and make code more functional.
Cyber Dungeon Quest
- together with the GDL scene2d API I have started developing the ‘property-editor’ for all the game properties like creatures, items, weapons, spells, etc. This required changes to consolidate the different properties into one
.ednfile and namespace.
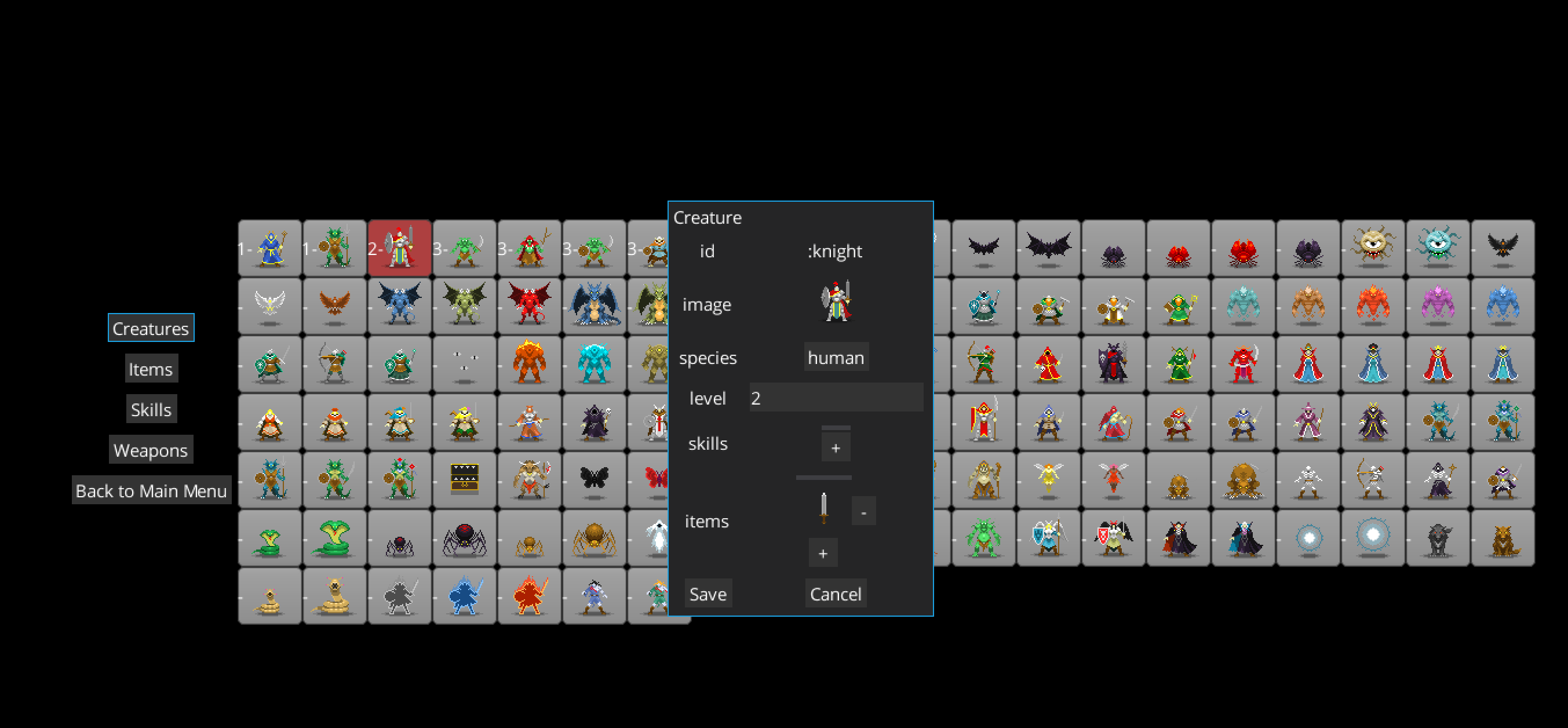
- a lot of cleanup/refactoring (the first version of the game I wrote 10 years back as a student so there is a lot of old code still included )
- the next task is to refactor ‘modifiers’ and ‘effects’ to make them data-based and editable too, and also to remove a lot of global state and make the code here also more functional.
Jank: Jeaye Wilkerson
2023 Q3 Funding Report 1. Published 15 October 2023.
For the past month and a half, I’ve been building out jank’s support for
clojure.core/require, including everything from class path handling to
compiling jank files to intermediate code written to the filesystem. This is a
half-way report for the quarter.
High level requirements
Class paths
Clojure JVM benefits a great deal from being built upon an existing VM. In the
native world, we don’t have things like class paths. Maybe the closest things
would be include paths at compile-time and LD_LIBRARY_PATH at run-time, but
neither of those capture the flexibility of JVM’s class paths, which work at both
compile-time and run-time.
So, to start with, jank needs a similar system. This is a common pattern for jank, requiring me to implement not just Clojure, but a VM of my own, with the necessary parts to reach parity.
Progress
I’ve built out class path traversing for jank, which supports both directories and JAR files. This will allow jank to work out of the box with Clojure’s existing Maven dependencies and file structures, which is of course important.
jank traverses the class path exhaustively on startup and caches what it finds,
mapping the module name (ns name or ns name with a nested class, like
clojure.core$foo) to the relevant file. When a function like require or
compile is called, jank will find the most relevant source to work with.
Core functions
There are a handful of related clojure.core functions for module loading, like
require, compile, load-libs, load-lib, load-one, load-all, alias, etc. The next step, after having class path support, is to implement these.
Progress
I have a working implementation of (require 'clojure.core) and (compile 'clojure.core) now! They hook into the class path work and do the necessary work to require or compile. Compilation writes files to a particular directory, which is also in the class path. Requiring a module which is already loaded will not do anything.
There’s still a lot of work to do to build out the necessary core functions and
have them work the same as in Clojure JVM. The implementations of require and
compile that I have right now only accept a single symbol, rather than
being variadic, supporting lib specs, flags, etc. So this is still an MVP, right
now, but it works!
Class files
There’s no such thing as a class file in the native world. Maybe the closest equivalent would be an object file or, for C++20, a pre-compiled module. Those are both more limiting than a class file, though, since they’re not portable; compiled native code is generally targeting a specific platform/architecture. Trying to share these in a Maven dependency, for example, is only going to help those who are on the same hardware as you. Even then, we can run into ABI Incompatibilities.
So, while I’m interested in exploring support for intermediate object files and pre-compiled modules, I’m starting with intermediate files being just C++ source (which is what the jank compiler outputs for Cling to JIT compile). From there, another step toward machine code will be to target LLVM IR by having Clang compile the C++ source first. This is closer to JVM byte code, but LLVM IR is actually still platform/architecture specific!
Lastly, I’m very hesitant to provide a default of jank dependencies coming in as binary files, even if I can solve the portability problem, simply due to supply chain security concerns. I would rather live in a world where people share source dependencies with pinned versions and transparent updates. I do think that binary intermediate files make sense for local development, though, and they can greatly speed up iteration.
Progress
As of now, I have (compile 'clojure.core) compiling jank source to C++ source,
which is being written to the class path. If you then later try to
(require 'clojure.core), it will be loaded from the compiled C++ source.
If the C++ source was on the class path already, it will be favored over the
jank source.
One benefit of this implementation is that jank developers can include
arbitrary C++ source along with their jank source and just require it
alongside everything else. In order to work with this, the C++ source just needs
to follow a particular interface.
A challenge I ran into with this is how to manage module dependencies. For
example, if clojure.core depends on clojure.core$take, which depends on a
local fn its own, clojure.core$take$fn_478, I need to ensure that all of these
are loaded in order of deepest dependency (leaf node) first. I went back on forth
on the design for this, but ultimately settled on something similar to what
Clojure does.
I generate two C++ source modules for clojure.core itself. One
is something like classes/clojure.core.cpp and the other is a special
classes/clojure.core__init.cpp. When clojure.core is required, it will look
for a clojure.core__init module first. Within that module is a special
interface with an __init function which has a big list of all of the
dependencies needed to actually load clojure.core. The __init function will
just iterate through that list and load each one.
Finally, we can actually load clojure.core, which runs the top-level effects of creating all of the vars, the value for each being based on new types brought in from the dependencies.
This is different from Clojure, since the JVM has a standard way for one module
to depend on another. That dependency is just conveyed, like using import in Java, and then the JVM ensures all dependencies are met before getting to the body of the module. Again, I need to reimplement that portion of the JVM for jank since the native world has no equivalent feature.
What’s remaining
Iterative compilation (tracking source timestamps to know how much to
recompile) and support for reloading have not been touched yet. Aside from that,
most things I have implemented are quite rough and need further polish to meet
parity with Clojure. Although I have require and compile working in the
simple case, none of the other related core functions have been implemented.
Performance wins so far
By pre-compiling clojure.core to C++ source, and then just requiring it on startup, the time it takes to boot the jank compiler + runtime and print hello world dropped from 8.7 seconds to 3.7 seconds. So that was all time spent compiling jank code to C++ code. What remains is almost entirely just time compiling C++. If I remove clojure.core loading altogether, it takes less than 0.2 seconds to run the same program. I’ll be digging more into the performance here, as I get more implemented, but I want to call out a couple of things.
- We’ve already cut 5 seconds down, which is great!
- Everyone knows that compiling C++ is not fast and we are set up to be able to start loading LLVM IR instead, after some more work
- The creator of Cling informed me that LLVM tends to spend around 50% of its time in the front-end for C++, which means that by using LLVM IR we’ll be cutting down our compilation time by around 50%
- I haven’t done any startup time benchmarking or profiling for jank yet, but if there’s time this quarter, you can bet that I’ll be digging deep into this
I have some exciting plans for visualizing jank’s performance, both the compiler
and your application code, in a way which will ship with the compiler itself.
More info on this in a later post.
Uncomplicate Neanderthal: Dragan Duric
2023 Q3 Funding Report 1. Published 30 September 2023.
My goal with this round is to polish Uncomplicate libraries (mainly Neanderthal, Deep Diamond, ClojureCUDA, ClojureCL, ClojureCPP), rather than develop new functionality.
In this round, I’ve done lots of Deep Diamond coding related to the port to JavaCPP. This enabled me to refresh my memory of how the very detailed and complex internal works, and to check and update many old tests, and write some, but not many, new tests. I am approaching the point where I would be able to say that all code is ported to JavaCPP pointers, and only then I’ll be able to work on documentation.
Here’s a breakdown of what I’ve been able to work on, regarding the proposed items:
- Do a thorough re-visiting of existing code in major Uncomplicate libraries: I’ve been able to re-visit many parts of this code, and did a lot of check and fixes. Still a lot left to be done.
- Read the code without rushing to implement new features: I haven’t been able to do it without implementing new features yet.
- Write more tests for edge cases: I’ve worked on this, but not as much as I hoped. Still a lot of work in front of me in this regard.
- Discover bugs and fix them: Discovered a fair amount, fixed most, but not all.
- Discover places where code could be improved (without rushing the new functionality). I’ve improved many parts of code, but without the benefit of not rushing to the new functionality. When I complete the JavaCPP switch of Deep Diamond, I’ll be able to do it in this manner.
- Re-visit documentation and improve it to better match the current state of Uncomplicate libraries: It has to wait for at least a few more weeks.
- If opportunities arise, implement some new functionality based of all the aforementioned items: I’ve done this here and there.
I hope that in the next few weeks I’ll be able to stabilize the JavaCPP-based Deep Diamond (DNNL engine port is complete, but cuDNN needs more work) and that then I’ll be able to do a systematic pass of testing/bugfixing/documentation writing.
Quil: Jack Rusher and Charles Comstock
2023 Q3 Funding Report 1. Published 30 September 2023.
So far, we’ve managed to:
- update all dependencies to the latest versions of Processing (4.3) and p5js (1.7.0), including packaging native deps for all major OSes
- re-wrote the build system using
deps.ednandbuild.clj - created a new test harness that allows side-by-side testing for Clojurescript (p5js) and Clojure (Processing)
- got that test harness working with CLJS in a headless browser on Github CI 🎉
These changes resolve the primary barriers to using Quil – requiring a deprecated version of the JVM (Java 8) in order to render OpenGL sketches, and incompatibility with the new Apple M1 architecture – and pave the way for easier maintenance moving forward. We still need to migrate a number of existing manual tests to the new test harness to improve overall coverage, but it’s a good foundation to build on. In the long run, this should reduce the difficulty of accepting new contributions and in cutting future releases.
Sam Aaron has added one of us to the Clojars organization for Quil, so we’re hoping to publish a SNAPSHOT of the current state of Quil on October 8 to facilitate wider user testing. There are a few breaking changes in terms of visual output that we’ve observed in our own sketches, but everything seems to mostly work, and Jack used this version of Quil to prepare slides for his talk at Strange Loop/Papers We Love Conference in September without problems.